Code
source("../appendix/packages.R")
source("../appendix/feature_labels.R")
# final dataset, for data wrangling see appendix
my_data <- read.csv("../data/analysis_df.csv")source("../appendix/packages.R")
source("../appendix/feature_labels.R")
# final dataset, for data wrangling see appendix
my_data <- read.csv("../data/analysis_df.csv")# weights and transformation
# Function to calculate various effect sizes and to estimate the variance
## for the traditional meta analysis
ies.da <- escalc(xi = event , ni = total , data = my_data ,
measure = "PFT", # FT double arcsine transformation
slab=paste(AuthorYear, " Estimate ", esid)
)
#the ies: individual effect size, new variables:
## yi: FTT effect sizes
## vi: calculated variances
ies.da$ancillary <- relevel(factor(ies.da$ancillary), ref = "Remote Sensing Only")
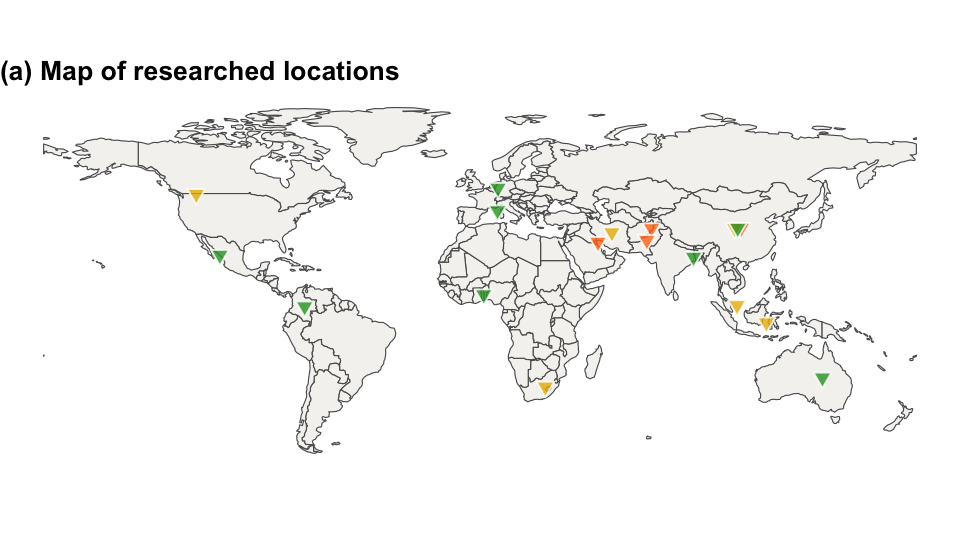
ies.da$indices <- relevel(factor(ies.da$indices), ref = "Not Used")A total of \(n = 20\) studies with \(k = 86\) effect sizes were included in this analysis, with each primary study reported between one and 27 results (\(1 \leq k_j \leq 27\)). The research area of these studies span 18 countries, Figure 4.1 shows a map indicating the location of each effect size. These primary studies were grouped into three different SDG goals: SDG 2 Zero Hunger, SDG 11 Sustainable Cities, and SDG 15 Life on Land.
sf_world <- ne_countries(returnclass = "sf")
# Get the world map data with country names, latitude, and longitude
world_map <- map_data("world")
SDG_colours <- c(
"SDG2: Zero Hunger" = "#E8B700",
"SDG11: Sustainable Cities" = "#FF7518",
"SDG15: Life on Land" = "#2C9F2C" )
study_map <- world_map |>
group_by(region) |>
summarize(lat = mean(lat), long = mean(long), .groups = 'drop')|>
right_join(subset(my_data, esid ==1), join_by("region"=="location"))
ggplot(sf_world) +
geom_sf(fill = "#f4f3f1")+
coord_sf(ylim = c(-55,80)) +
geom_jitter(data = study_map, aes(x = long, y = lat,
fill = SDG_theme),
size = 2,
width = 5,
colour = "transparent",
alpha = 0.8,
height = 0,
shape = 25,
show.legend = FALSE) +
labs(title = "(a) Map of researched locations",
x = NULL,
y = NULL) +
scale_fill_manual(values = SDG_colours ) +
common_theme +
theme(
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank(),
panel.border = element_blank(),
plot.margin = margin(0, 0, 0, 0)
)
ggplot(ies.da, aes(x = reorder(AuthorYear, OA_reported), y = OA_reported,
colour = SDG_theme
))+
geom_point(alpha = 0.2, size = 1.5)+
stat_summary(geom = "point", fun = "mean",
size = 2, shape = 17)+
labs(x = NULL,
y = "Observed Overall Accuracy",
title = "(B) Reported overall accuracy by study") +
scale_colour_manual(values = SDG_colours ) +
guides(colour=guide_legend(title= NULL, nrow=1, byrow=TRUE,
override.aes = list(shape = 16, size = 2.5)
)
)+
coord_flip() +
common_theme+
theme(# grid lines
panel.grid.major.y = element_line(linewidth = 0.1, colour = "grey80"),
# legend specs
legend.position = "bottom",
legend.key.size = unit(0, 'lines'),
legend.key.spacing.x = unit(-2.5, "lines"),
legend.text= element_text(size=8, margin = margin(l = -0.3, r = 1.5, unit = "cm")),
plot.margin = margin(t= 2, b = 0, r= 0.1, l =0, "cm"),
legend.box.margin = margin(t= -0.4, b = 0, r= 0, l =0, "cm")
)
shapiro_test_result <- round(shapiro_test(ies.da$yi)[, 2:3], 2)@#fig-map_range (b) and Table 4.1 (bellow) show, the reported overall accuracies are not centered around 0.5. Therefore, a transformation is required. Figure 4.2 shows the distribution of observed overall accuracy as well as the logit and FT transformation values. FT visually performs better than the Logit transformation. However the Shapiro-Wilk Normality test shows that the distribution of the FT transformed overall accuracy still departed significantly from normality (\(W =\) 0.93, p-value < 0.01). Nevertheless, conducting a meta-analysis remains justified, as these statistical models are generally robust against violations of normality (McCulloch & Neuhaus, 2011).
raw_propotions <- ggplot(ies.da, aes(x = OA_reported))+
geom_histogram(bins = 30, fill = "#001158", alpha = .8) +
labs(x = "Observed Overall Accuracy", y = "Count") +
common_theme
logit_transformation <- ggplot(ies.da, aes(x = log(OA_reported/(1-OA_reported))))+
geom_histogram(bins = 30, fill = "#001158", alpha = .8)+
labs(x = "Logit-transformed Overall Accuracy", y = NULL) +
common_theme
arcsin_transformation<- ggplot(ies.da, aes(x = yi))+
geom_histogram(bins = 30, fill = "#001158", alpha = .8)+
labs(x = "FT-transformed Overall Accuracy", y = NULL)+
common_theme
raw_propotions + logit_transformation+ arcsin_transformation +
plot_annotation(title = "Density Plots of Observed and Transformed Overall Accuracy",
theme = theme(plot.title = element_text(size = 10)))![]()
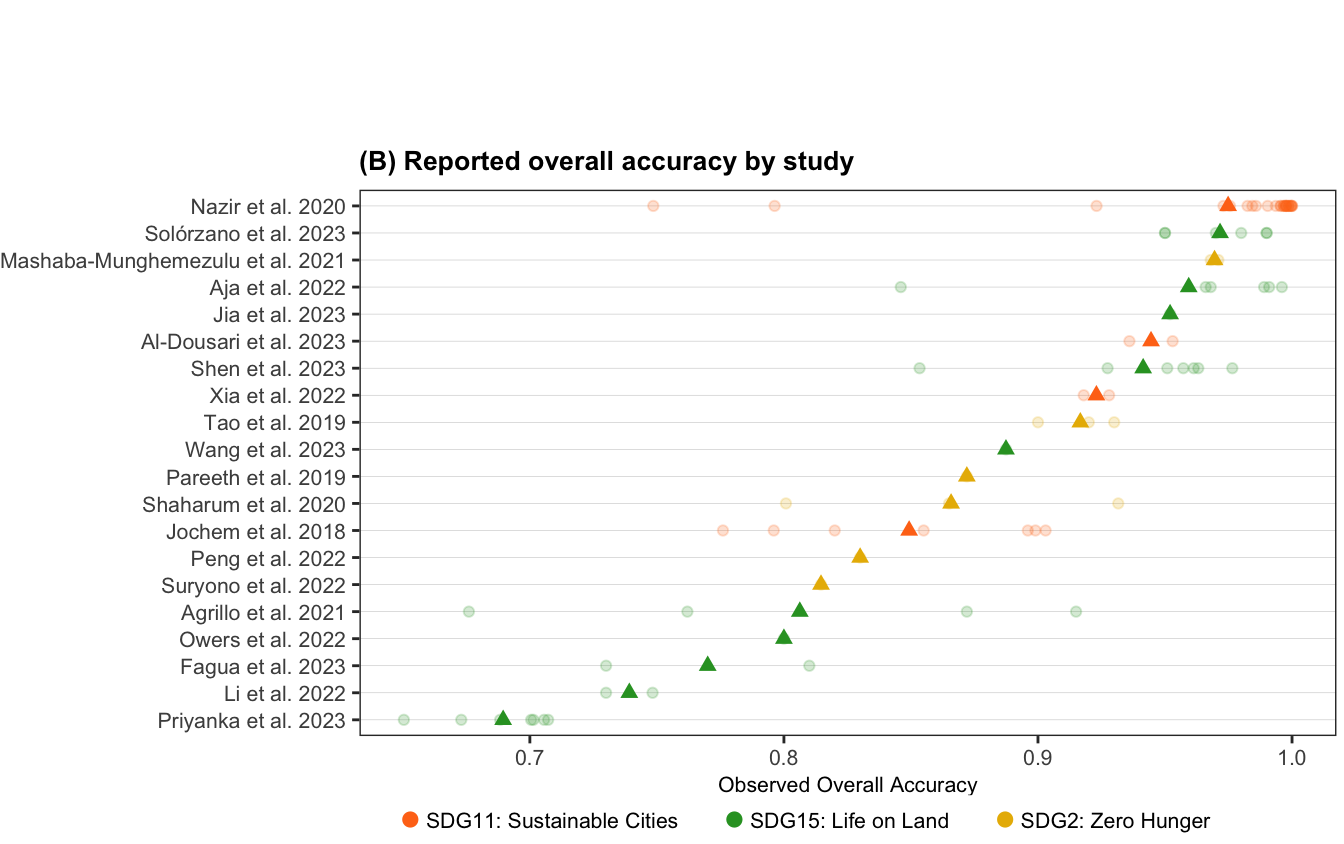
Table 4.1 summarises the overall accuracy (effect size of interest), study sample size and the collected study features, including the study features such as sample size, overall accuracy, types of machine learning models used and SDG goal targeted. For the meta-analysis the range of the sample size (259 - 75782016) and overall accuracy (0.6504 - 1) are of importance. Most studies used Neural Networks (48%), followed by Tree-Based Models (45%), and a small portion used other types of models (7%). Regarding SDGs, 44% of the studies aimed at SDG 11 (Sustainable Cities), 43% targeted SDG 15 (Life on Land), and 13% focused on SDG 2 (Zero Hunger).
ies.da |>
select(
OA_reported,
total,
globalCitationsCount,
number_classes,
fraction_majority_class,
Publication.Year,
SDG_theme,
classification_type,
model_group,
ancillary,
indices,
RS_device_type,
RS_device_group,
no_band_group,
RS_spatital_res_grouped,
Confusion_matrix
) |>
tbl_summary(
statistic = list(
all_continuous() ~ "{mean} ({min} - {max})",
all_categorical() ~ "{n} ({p}%)"
),
label = feature_labels,
missing = "no"
) |>
modify_header(label = "Feature") |>
modify_header(all_stat_cols() ~ "Statistic") |>
as_kable(
booktabs = TRUE,
longtable = TRUE,
linesep = "",
escape = TRUE
)|>
kable_styling(font_size = 9,
full_width = FALSE)|>
pack_rows("Study Features", 2, 46, latex_gap_space = "0.1em" #, hline_before = T
)|>
pack_rows("Numeric$^b$", 2, 5, latex_gap_space = "0em")|>
pack_rows("Categorical$^c$", 6,46, latex_gap_space = "0em")|>
row_spec(c(0), bold = TRUE)|>
column_spec(1, width = "7cm")|>
column_spec(2, width = "6cm")|>
add_indent(c(7:12, 14:16, 18:20, 22:24, 26:27,
29:30, 32:35,37:40,42:44,
46:48),
level_of_indent = 1.5)|>
footnote(alphabet = c("Effect size of interest. $^a$For numeric predictors: mean (min - max) and $^b$ for categorical variables number of effect sizes (%)"),
threeparttable=TRUE, escape = FALSE)| Feature | Statistic |
|---|---|
| Overall Accuracy | 0.90 (0.65 - 1.00) |
| Study Features | |
| Numeric$^b$ | |
| Sample Size | 6,401,352 (259 - 75,782,016) |
| Number of Citations | 15 (2 - 68) |
| Number of Classes | 4 (2 - 13) |
| Majority-class Proportion | 0.72 (0.14 - 1.00) |
| Categorical$^c$ | |
| Publication Year | |
| 2018 | 7 (8.1%) |
| 2019 | 4 (4.7%) |
| 2020 | 30 (35%) |
| 2021 | 6 (7.0%) |
| 2022 | 13 (15%) |
| 2023 | 26 (30%) |
| SDG Theme | |
| SDG11: Sustainable Cities | 38 (44%) |
| SDG15: Life on Land | 37 (43%) |
| SDG2: Zero Hunger | 11 (13%) |
| Classification Type | |
| Object-level | 46 (53%) |
| Pixel-level | 36 (42%) |
| Unclear | 4 (4.7%) |
| Model Group | |
| Neural Networks | 41 (48%) |
| Other | 6 (7.0%) |
| Tree-Based Models | 39 (45%) |
| Ancillary Data | |
| Remote Sensing Only | 71 (83%) |
| Ancillary Data Included | 15 (17%) |
| Indices | |
| Not Used | 23 (27%) |
| Used | 63 (73%) |
| Remote Sensing Type | |
| Active | 11 (13%) |
| Combined | 7 (8.1%) |
| Not Reported | 7 (8.1%) |
| Passive | 61 (71%) |
| Device Group | |
| Landsat | 15 (17%) |
| Not Reported | 7 (8.1%) |
| Other | 44 (51%) |
| Sentinel | 20 (23%) |
| Number of Spectral Bands | |
| Low | 18 (21%) |
| Mid | 26 (30%) |
| Not Reported | 42 (49%) |
| Spatial Resolution | |
| <1 metre | 7 (8.1%) |
| 10-30 metres | 39 (45%) |
| Not Reported | 40 (47%) |
| Confusion Matrix | |
| Not Reported | 23 (27%) |
| Reported | 63 (73%) |
| a Effect size of interest. $^a$For numeric predictors: mean (min - max) and $^b$ for categorical variables number of effect sizes (%) | |
# common aesthetics
box_theme <- common_theme + theme(axis.title.y = element_blank())
point_color <- "#001158"
ylab <- c("FT Transformed Overall Accuracy")
# Scatter plots for continuous variables
sample_size <- ggplot(ies.da, aes(x = log10(total), y = yi)) +
geom_point(size = 1, alpha = 0.8, colour = point_color) +
labs(title = feature_labels$total,
y = ylab,
x = bquote("Sample Size:"~log[10](m[ij])),
#caption = stringr::str_wrap("Note: Log transformation was applied to handle large variation in sample sizes", width = 42)
) +
#expand_limits(x = 0)+
common_theme #+
#theme(plot.caption = element_text(size = 7.5, hjust = 0, color = "gray30",
# margin = margin(t = 5, r = 0, b = 20, l = 0)))
number_class <- ggplot(ies.da, aes(x = number_classes, y = yi)) +
geom_point(size = 1, alpha = 0.8, colour = point_color) +
labs(title = feature_labels$number_classes, y = ylab, x = "Classes") +
scale_x_continuous(breaks=seq(0, 13, 2))+
expand_limits(x = 0)+
common_theme
fraction_majority_class <- ggplot(ies.da, aes(x = fraction_majority_class, y = yi)) +
geom_point(size = 1, alpha = 0.8, colour = point_color) +
labs(title = feature_labels$fraction_majority_class,
y = ylab,
x = "Proportion") +
expand_limits(x = 0)+
common_theme
cits <- ggplot(ies.da, aes(x = globalCitationsCount , y = yi)) +
geom_point(size = 1, alpha = 0.8, colour = point_color) +
labs(title = feature_labels$globalCitationsCount,
y = ylab,
x = "Citation") +
expand_limits(x = 0)+
common_theme
#######################
# Boxplots for categorical variables
modelgroup_box <- ggplot(ies.da, aes(y = yi,
x = factor(model_group,
levels = c("Other",
"Neural Networks",
"Tree-Based Models")))) +
geom_boxplot() +
geom_jitter(colour = point_color, alpha = 0.7) +
scale_x_discrete_wrap() +
labs(title = feature_labels$model_group,
y = NULL) + # patchwork collect x.axis not being agreeable manual selection
coord_flip() + box_theme
classtype_box <- ggplot(ies.da, aes(y = yi, x = fct_rev(classification_type))) +
geom_boxplot() +
geom_jitter(colour = point_color, alpha = 0.7) +
labs(title = feature_labels$classification_type,
y = ylab) +
coord_flip() + box_theme
indexes_box <- ggplot(ies.da, aes(y = yi, x = indices)) +
geom_boxplot() +
geom_jitter(colour = point_color, alpha = 0.7) +
labs(title = feature_labels$indices, y = ylab) +
coord_flip() + box_theme
ancillary_box <- ggplot(ies.da, aes(y = yi, x = ancillary)) +
geom_boxplot() +
geom_jitter(colour = point_color, alpha = 0.7) +
scale_x_discrete_wrap() +
labs(title = feature_labels$ancillary, y = NULL) +
coord_flip() + box_theme
# Data about RS devices and features
RStype_box <- ggplot(ies.da, aes(y = yi, x = factor(RS_device_type,
levels = c("Not Reported", "Combined", "Passive","Active")))) +
geom_boxplot() +
geom_jitter(colour = point_color, alpha = 0.7) +
scale_x_discrete_wrap() +
labs(title = feature_labels$RS_device_type, y = NULL) +
coord_flip() + box_theme
RSgroup_box <- ggplot(ies.da, aes(y = yi,
x = factor(RS_device_group,
levels = c("Not Reported", "Other", "Sentinel","Landsat")))) +
geom_boxplot() +
geom_jitter(colour = point_color, alpha = 0.7) +
labs(title = feature_labels$RS_device_group, y = NULL) +
coord_flip() + box_theme
RS_resolution_box <- ggplot(ies.da, aes(y = yi, x = fct_rev(RS_spatital_res_grouped))) +
geom_boxplot() +
geom_jitter(colour = point_color, alpha = 0.7) +
labs(title = feature_labels$RS_spatital_res_grouped, y = ylab) +
coord_flip() + box_theme
SDG_theme_box <- ggplot(ies.da,
aes(y = yi, x = factor(SDG_theme,
levels = c("SDG2: Zero Hunger",
"SDG11: Sustainable Cities",
"SDG15: Life on Land")))) +
geom_boxplot() +
geom_jitter(colour = point_color, alpha = 0.7) +
scale_x_discrete_wrap() +
labs(title = feature_labels$SDG_theme, y = NULL) +
coord_flip() + box_theme
publication_year_box <- ggplot(ies.da, aes(x = as.factor(Publication.Year), y = yi)) +
geom_boxplot() +
geom_jitter(colour = point_color, alpha = 0.7) +
labs(title = feature_labels$Publication.Year, y = ylab) +
coord_flip() + box_theme
no_band_group_box <- ggplot(ies.da, aes(y = yi, x = fct_rev(no_band_group))) +
geom_boxplot() +
geom_jitter(colour = point_color, alpha = 0.7) +
labs(title = feature_labels$no_band_group, y = ylab) +
coord_flip() + box_theme
confusion_matrix_box <- ggplot(ies.da, aes(y = yi, x = Confusion_matrix)) +
geom_boxplot() +
geom_jitter(colour = point_color, alpha = 0.7) +
labs(title = feature_labels$Confusion_matrix, y = NULL) +
coord_flip() + box_theme# layout areas
design <- c(
area(1, 1, 2, 1),
area(1, 2),
area(1, 3),
area(1, 4),
area(2, 2),
area(2, 3),
area(2, 4),
area(3, 1),
area(3, 2),
area(3, 3),
area(3, 4)
)
publication_year_box + SDG_theme_box + classtype_box + modelgroup_box +
ancillary_box + indexes_box + RStype_box + no_band_group_box +
RSgroup_box + RS_resolution_box + confusion_matrix_box +
plot_layout(design = design)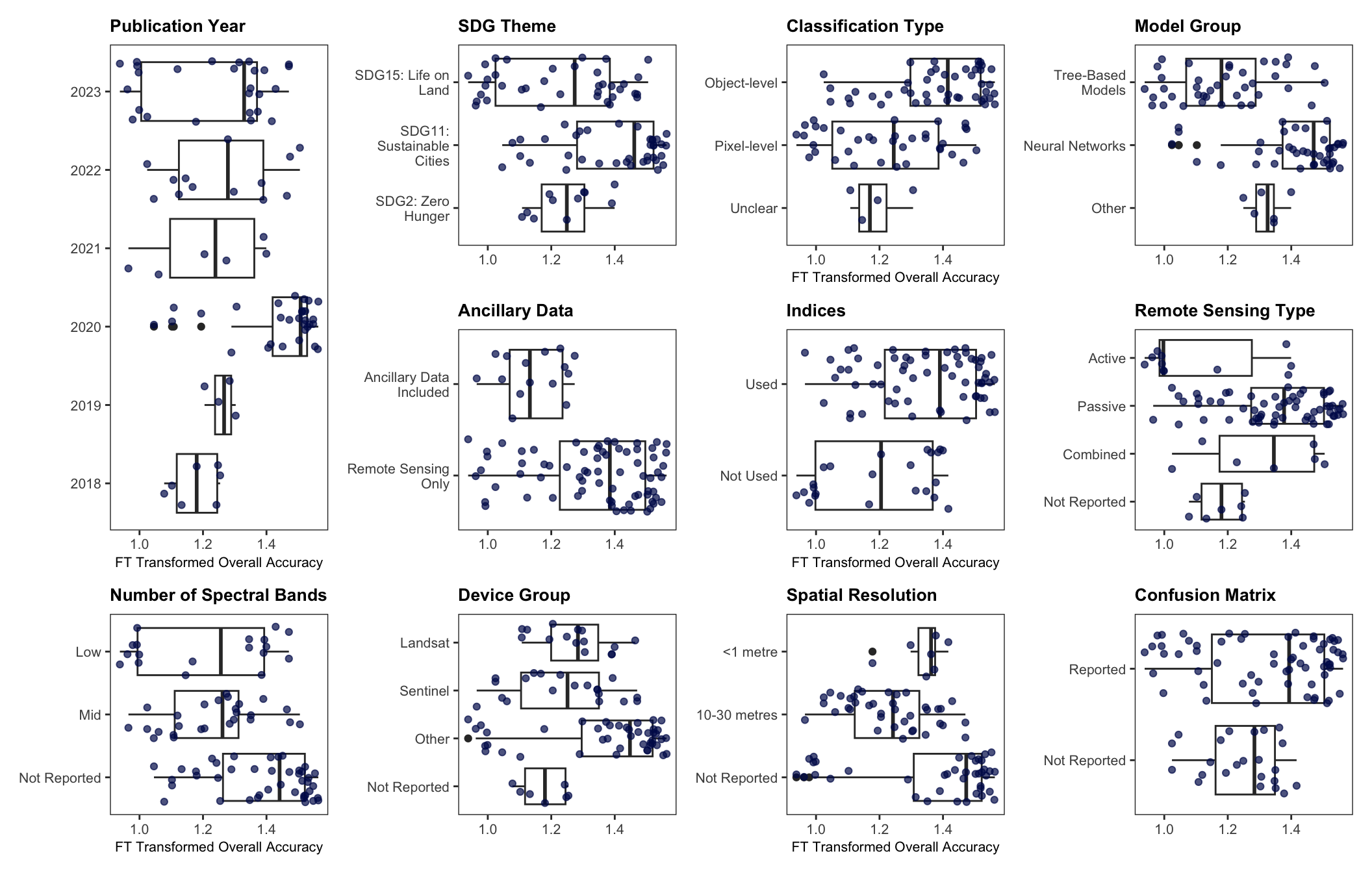
fraction_majority_class + cits +
number_class + sample_size +
plot_layout(axis_titles = 'collect_y', ncol = 2)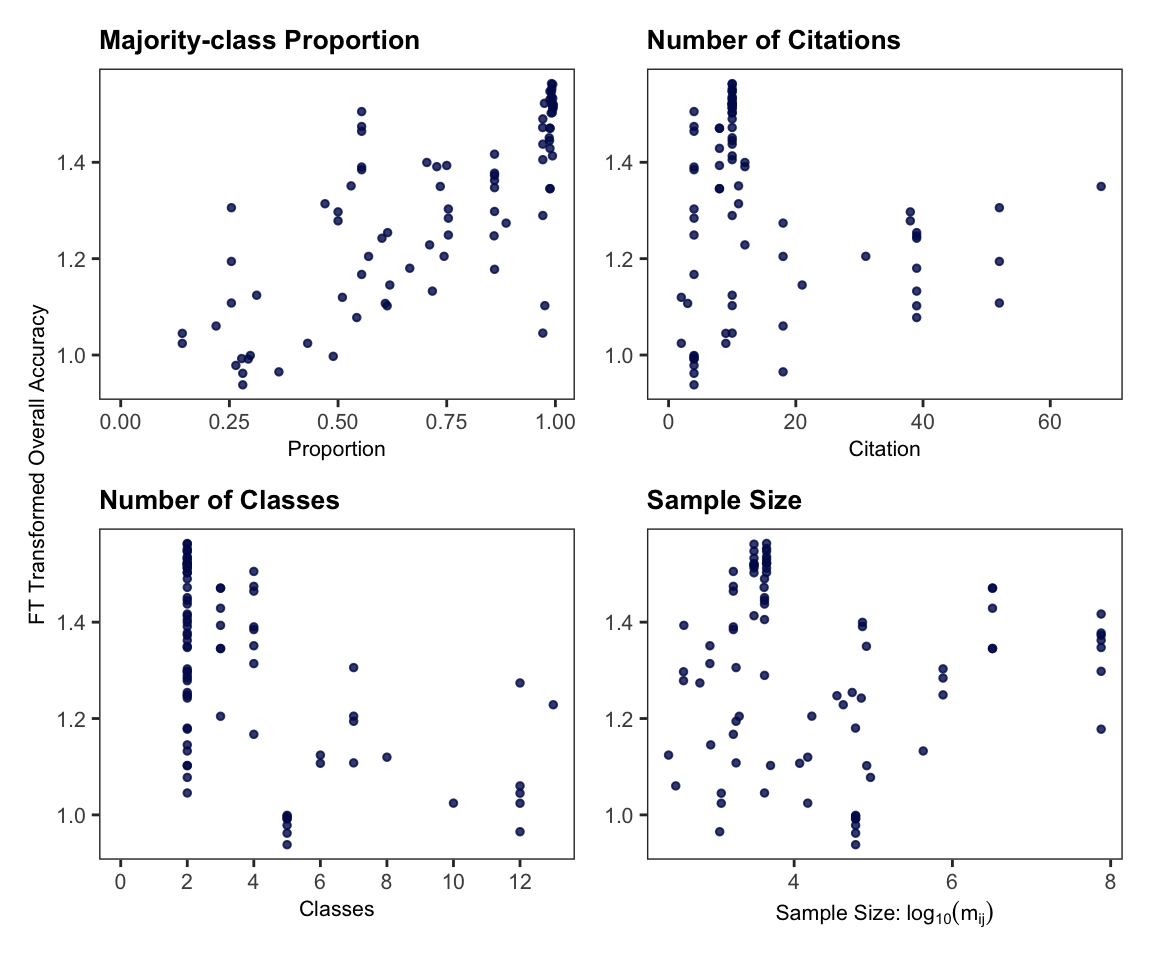
# METHOD: Weighted: level 2 model
## pes: pooled effect size
pes.da <- rma(yi,
vi,
data = ies.da,
method = "REML",
test = "t")# METHOD: Weighted: Nested level 3model
pes.da.lvl3 <- rma.mv(yi,
vi,
data = ies.da ,
tdist = TRUE,
# adding random effects at the study level and effect size
random = ~ 1 | AuthorYear / esid,
method = "REML",
# recommendations from the function documentation:
test="t",
dfs="contain"
)
#summary(pes.da.lvl3)pes <- predict(pes.da.lvl3, transf = transf.ipft.hm, targ = list(ni=1/(pes.da.lvl3$se)^2))
pes.da.lvl3_I_squared <- dmetar::var.comp(pes.da.lvl3)
pes.da.lvl3_CI <- confint(pes.da.lvl3)
results <- data.frame(
theta = pes$pred,
ci_l = pes$ci.lb,
ci_u = pes$ci.ub,
sigma2.1 = pes.da.lvl3$sigma2[1],
sigma2.2 = pes.da.lvl3$sigma2[2],
df = pes.da.lvl3$QEdf,
Q = pes.da.lvl3$QE,
p = pes.da.lvl3$QEp,
I_L2 = pes.da.lvl3_I_squared$results$I2[2],
I_L3 = pes.da.lvl3_I_squared$results$I2[3]
)
row.names(results) <-"RE_lvl3"
# results$theta
# # same as
# v_bar <- (pes.da.lvl3$se)^2
# t_bar <- pes.da.lvl3$b[1]
# (1/2 * (1 - sign(cos(2*t_bar)) *
# sqrt(1 - (sin(2*t_bar)+(sin(2*t_bar)-1/sin(2*t_bar))/(1/v_bar))^2)))
# #profile likelihood plots of the variance components of the model
#par(mfrow=c(2,1))
#profile(pes.da.lvl3, sigma2=1)
#profile(pes.da.lvl3, sigma2=2)
# METHOD 1.2:
# multivariate parameterization model
# this is a multilvl rather than a nested model (if since the samples could be different data or countries this might be the better approch?)
pes.da.lvl3.mv <- rma.mv(yi,
vi,
data = ies.da,
random = ~ esid|AuthorYear,
method = "REML",
# recomendations from the function detains +Assink et.al:
tdist = TRUE,
test="t",
dfs="contain"
)
# should be exactly the same
#logLik(pes.da.lvl3)
#logLik(pes.da.lvl3.mv)
# future research look into different variance-covariance matrix structures#
W <- weights(pes.da.lvl3, type="matrix")
X <- model.matrix(pes.da.lvl3)
y <- cbind(ies.da$yi)
solve(t(X) %*% W %*% X) %*% t(X) %*% W %*% y
# weights of pixel- vs weights of object- based studies
ies.da$weights <- weights(pes.da.lvl3, type = "rowsum")
hist(ies.da$weights)
ggplot(ies.da, mapping = aes(classification_type, weights))+
geom_boxplot()+
geom_jitter(aes(colour = AuthorYear), alpha = 0.7)
t.test(weights~classification_type,
# removing unclear
data = subset(ies.da, ies.da$classification_type != "Unclear"))
ggplot( subset(ies.da, ies.da$classification_type != "Unclear"),
mapping = aes(classification_type, weights))+
geom_boxplot()# To visualize results aggregate model
### assume that the effect sizes within studies are correlated with
V <- vcalc(vi, cluster=AuthorYear, obs=esid, data=ies.da, rho=pes.da.lvl3.mv$rho)
### fit multilevel model using this approximate V matrix
pes_agg.da.lvl3 <- rma.mv(yi, V, random = ~ 1 | AuthorYear/esid, data=ies.da)
agg <- aggregate(ies.da, cluster=AuthorYear, V=vcov(pes_agg.da.lvl3, type="obs"), addk=TRUE)
agg.pes.da <- rma(yi, vi, method="EE", data=agg, digits=3)
agg.pes <- predict(agg.pes.da , transf = transf.ipft.hm, targ =list(ni=1/(pes.da.lvl3$se)^2))
# forest plot:
model_summary <- bquote(paste("RE (3-Level) Model ",
"(Q = ",
.(fmtx(results$Q[1], digits=0)),
", df = ",
.(fmtx(results$df[1], digits=0)),
", p <.001; ",
I^2, " = 100% ",
sep = ""))
png(file='forestplot_weighted.png', width = 1000, height = 800)
forest(agg.pes.da,addpred=TRUE,
xlim=c(-2,2.5),
alim =c(0, 1),
transf = transf.ipft.hm, targ =list(ni=1/(pes.da.lvl3$se)^2),
header=TRUE,
slab=AuthorYear,
order="obs",
cex=1.5,
refline=NA,
digits = 3,
ilab=ki,
mlab= model_summary,
ilab.xpos= -.3,
ilab.pos = 2,
#showweights = TRUE,
shade="zebra"
)
text(-.5, agg.pes.da$k+2, "OA Count", cex=1.5, font=2)
text(2.1, agg.pes.da$k+3, "Weighted", cex=1.5, font=2)########################
# METHOD 2: UnWeighted
# the mean of the yi should be the estimate of effect
pes.da.lvl3_unweighted <- rma.mv(yi = yi,
V = 1,
random = ~ 1 | AuthorYear / esid, # Nested random effects
data = ies.da,
method = "REML",
tdist = TRUE,
test="t",
dfs="contain")
#summary(pes.da.lvl3_unweighted)
#mean(ies.da$yi)
pes_u <- predict(pes.da.lvl3_unweighted, transf = transf.ipft.hm, targ = list(ni=1/(pes.da.lvl3_unweighted$se)^2))
theta_u <- mean(ies.da$OA_reported)
t_critical <- qt(0.975, 19)
se <- 1 / sqrt(86)
results["Unwei_rma.mv"] <- NA
results["Unwei_rma.mv", 1:3 ]<- c(pes_u$pred, pes_u$ci.lb, pes_u$ci.ub)
results<- results|> mutate_if(is.numeric, round, digits=3)# To visualize results aggregate model
### assume that the effect sizes within studies are correlated with
V <- vcalc(vi, cluster=AuthorYear, obs=esid, data=ies.da, rho=0.6)
### fit multilevel model using this approximate V matrix
pes_agg.unweighted <- rma.mv(yi, V, random = ~ 1 | AuthorYear/esid, data=ies.da)
agg <- aggregate(ies.da, cluster=AuthorYear, V=vcov(pes_agg.unweighted, type="obs"), addk=TRUE)
agg.pes.da <- rma(yi, vi, method="EE", data=agg, digits=3)
agg.pes <- predict(agg.pes.da , transf = transf.ipft.hm, targ =list(ni=1/(pes.da.lvl3_unweighted$se)^2))
# forest plot:
png(file='forestplot_unweighted.png', width = 1000, height = 800)
forest(agg.pes.da,addpred=TRUE,
xlim=c(-2,2.5),
alim =c(0, 1),
transf = transf.ipft.hm, targ =list(ni=1/(pes.da.lvl3_unweighted$se)^2),
header=TRUE,
slab=AuthorYear,
order="obs",
refline=NA,
col = "#001158",
cex=1.5,
digits = 3,
ilab=ki,
mlab= "Unweighted Model",
ilab.xpos= -.3,
ilab.pos = 2,
#showweights = TRUE,
shade="zebra"
)
text(-.5, agg.pes.da$k+2, "OA Count", cex=1.5, font=2)
text(2.1, agg.pes.da$k+3, "Unweighted", cex=1.5, font=2)The forest plot below (Figure 4.5) compares the overall accuracy effect size across studies using both weighted and unweighted models, with error bars which correspond to the weighted model — at this scale there is no discernible difference between the error bars of the two models. Each study is given with the number of estimates per study \(k_j\), and study average effect size (\(\kappa_j\)), with 95% confidence intervals (CI), both for the weighted and unweighted model. Of the 20 primary studies included, six reported only one effect. Based on the unweighted model, the average accuracy of machine learning methods applied to remote sensing data is 0.90 (95% CI[0.85; 0.94]). While the three-level meta-analytic model produced an average accuracy of 0.89 (95% CI[0.85; 0.93]). This implies, that on average, the machine learning methods correctly classify around 90% of the time when applied to remote sensing data.
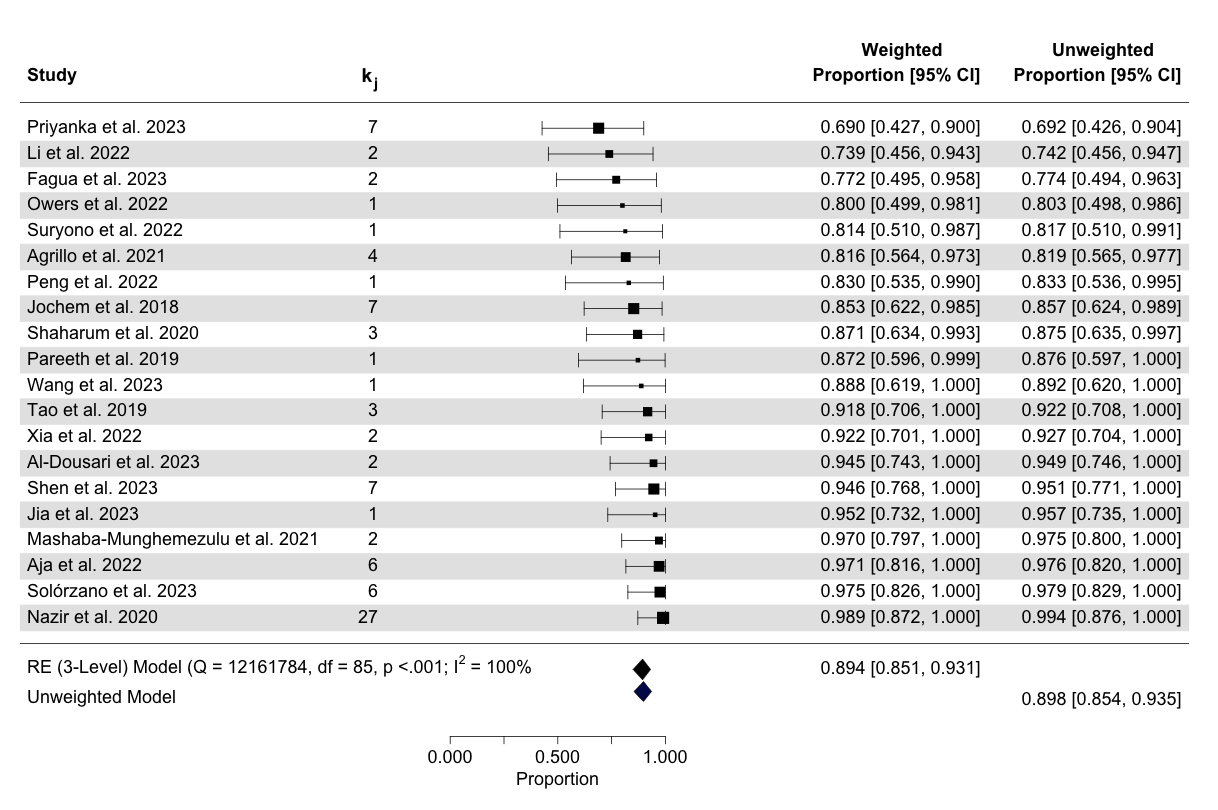
The heterogeneity metrics Cochran’s Q indicate significant heterogeneity of the reported overall acccuracies. The percentage of the variance attribution is \(I^2_{\text{level3}}\) = 63.62% which is the fraction of the variation that can be attributed to between-study, and \(I^2_{\text{level2}}\) = 36.38% which is within-study heterogeneity, with negligible fixed effect variance (variance due to sampling error). The \(I^2\) value of 100% indicates that all the observed variability in effect sizes across studies is due to heterogeneity rather than sampling error, suggesting substantial differences between the studies and a high degree of variation in their results.
Using the multi-model inference function, a total of 31,298 models converged . Figure 4.6, illustrates the predictor importance after evaluating all possible combinations of predictors to identify which combination provides the best fit and which predictors are most influential. Higher importance values indicate more consistent inclusion in high-weight models. The majority class proportion is the most important predictor, followed by the inclusion of ancillary data. Less influential predictors include used of indices, sample size, publication year, and the number of classes in the study. Meanwhile, factors such as classification type, SDG goal, machine learning group, spatial resolution, and citation count have minimal importance in the overall model performance (i.e., were not included in the models top performing models according to AIC).
study_features <- c("model_group", "indices", "SDG_theme", "classification_type",
"Confusion_matrix", "RS_device_type", "RS_device_group", "RS_spatital_res_grouped",
"ancillary", "no_band_group", "Publication.Year", "total",
"globalCitationsCount", "number_classes", "fraction_majority_class"
)
ies.da$se <- sqrt(ies.da$vi)
multi_inf <- multimodel.inference(TE = "yi",
seTE = "se",
method='REML',
test='t',
data = ies.da,
predictors = study_features,
interaction = FALSE,
seed=357)
multi_inf$predictor.importance.plot+
scale_x_discrete(labels = feature_labels)+
labs(x = NULL,
title = "Model-averaged predictor importance plot" )+
theme_apa()+
common_theme
ggsave("figures/fig-best_mod.png", height =4, width = 7)
#saveRDS(multi_inf, "../appendix/multimodel_inference_out.rda")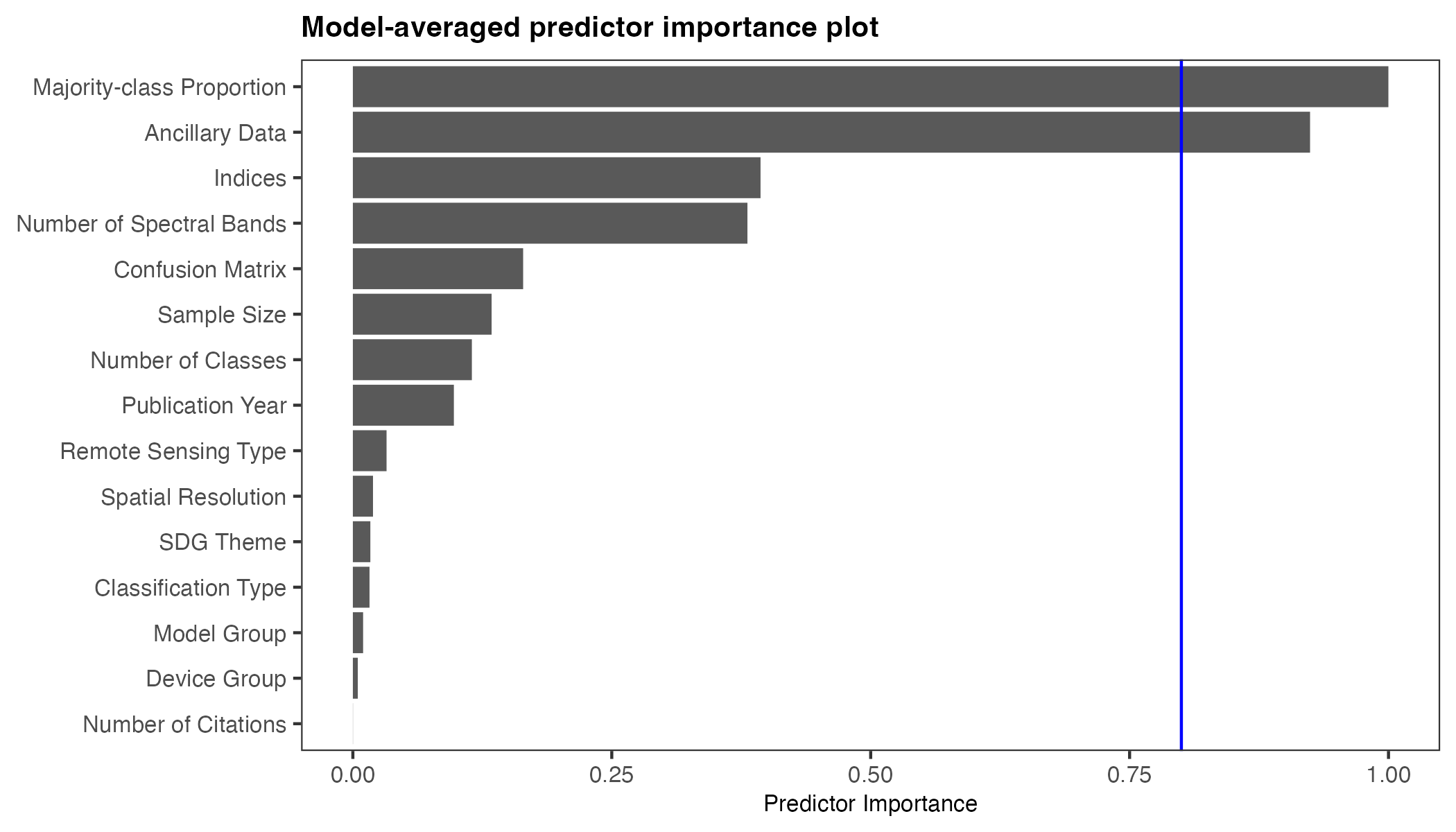
In the multimodel inference analysis, the five best-performing models were identified based on their AIC scores. The selected top models consistently included key predictors such as the majority-class proportion and the use of ancillary data. Table 4.2 shows the results of the multi-model inference. The significant study features are the majority-class proportion and the inclusion of ancillary data. Interestingly, the use of ancillary data has a negative effect on overall accuracy in the FT transformed scale. Table 4.3 shows these best performing models and the intercept-only model (before adding the predictors), note that the AIC is very similar in among the top five.
multi_coef<- read_excel("figures/summary_tables.xlsx",
sheet = "multimodel_inference_results")
kable(
multi_coef,
booktabs = TRUE,
linesep = "",
col.names = c("Importance", "Feature (Referance Category)",
"Comparison Category", "b", "SE", "z", "p"),
)|>
kable_styling(font_size = 9.5,
full_width = FALSE)|>
row_spec(c(0), bold = TRUE)|>
footnote(c("Importace of each feature, the reference and combarsion categories given with their estimated coefficients (b), standard errors (SE) on the FT transformed scale with correstponding z- and p-values."), threeparttable=T)| Importance | Feature (Referance Category) | Comparison Category | b | SE | z | p |
|---|---|---|---|---|---|---|
| NA | Intercept | na | 1.29 | 7.85 | 0.16 | 0.869 |
| 1.00 | Majority-class Proportion | na | 0.47 | 0.08 | 6.15 | 0.000 |
| 0.92 | Ancillary Data (Remote Sensing Only) | Ancillary Data Included | -0.12 | 0.05 | 2.33 | 0.020 |
| 0.39 | Indices (Not Used) | Used | 0.03 | 0.04 | 0.67 | 0.500 |
| 0.38 | Number of Spectral Bands (Low) | Mid | 0.05 | 0.06 | 0.72 | 0.471 |
| NA | na | Not Reported | 0.02 | 0.04 | 0.55 | 0.581 |
| 0.16 | Confusion Matrix (Not reported) | Reported | 0.01 | 0.02 | 0.29 | 0.776 |
| 0.13 | Sample Size | na | 0.00 | 0.00 | 0.10 | 0.922 |
| 0.11 | Number of Classes | na | 0.00 | 0.00 | 0.19 | 0.846 |
| 0.10 | Publication Year | na | 0.00 | 0.00 | 0.06 | 0.952 |
| 0.03 | Remote Sensing Type (Active) | Passive | 0.00 | 0.02 | 0.16 | 0.870 |
| NA | na | Combined | 0.01 | 0.03 | 0.17 | 0.869 |
| NA | na | Not Reported | 0.00 | 0.02 | 0.04 | 0.971 |
| 0.02 | Spatial Resolution ( <1 metre) | 10-30 metres | 0.00 | 0.07 | 0.01 | 0.990 |
| NA | na | Not Reported | 0.00 | 0.07 | 0.00 | 0.996 |
| 0.02 | SDG Theme (SDG11:Sustainable Cities) | SDG2: Zero Hunger | 0.00 | 0.01 | 0.08 | 0.939 |
| NA | na | SDG15: Life on Land | 0.00 | 0.01 | 0.10 | 0.924 |
| 0.02 | Classification Type (Object-level) | Pixel-level | 0.00 | 0.01 | 0.06 | 0.955 |
| NA | na | Unclear | 0.00 | 0.01 | 0.05 | 0.958 |
| 0.01 | Model Group (Neural Networks) | Tree-Based Models | 0.00 | 0.01 | 0.05 | 0.961 |
| NA | na | Other | 0.00 | 0.01 | 0.04 | 0.965 |
| 0.00 | Device Group (Landsat) | Sentinel | 0.00 | 0.01 | 0.05 | 0.959 |
| NA | na | Not Reported | 0.00 | 0.01 | 0.05 | 0.956 |
| NA | na | Other | 0.00 | 0.00 | 0.05 | 0.963 |
| 0.00 | Number of Citations | na | 0.00 | 0.00 | 0.01 | 0.995 |
| Note: | ||||||
| Importace of each feature, the reference and combarsion categories given with their estimated coefficients (b), standard errors (SE) on the FT transformed scale with correstponding z- and p-values. |
multi_inf<- readRDS("../appendix/multimodel_inference_out.rda")
models <- data.frame(
#Model.no = c(42, 138, 10, 142, 16522, 1),
"Candidate models" = c("Ancillary Data + Majority-class Proportion + Indices",
"Ancillary Data + Majority-class Proportion + Number of Spectral Bands",
"Ancillary Data + Majority-class Proportion",
"Ancillary Data + Confusion Matrix + Majority-class Proportion + Number of Spectral Bands",
"Ancillary Data + Majority-class Proportion + Number of Spectral Bands + Sample Size",
"Intercept-Only"),
"df" = c(multi_inf$top5.models$df, 2),
AICc = c(multi_inf$top5.models$AICc, -41.93257),
"Akaike weights" = c(multi_inf$top5.models$weight, 2.444007e-17)
)
kable(
models,
booktabs = TRUE,
escape = FALSE,
linesep = c("\\addlinespace \\addlinespace"),
col.names = c("Candidate models", "df", "AIC$_c$", "Akaike weights"),
digits = c(0,0, 2, 2,2)
)|>
kable_styling(font_size = 9.5,
full_width = FALSE)|>
row_spec(c(0), bold = TRUE)|>
column_spec(1, width = "9cm")| Candidate models | df | AIC$_c$ | Akaike weights |
|---|---|---|---|
| Ancillary Data + Majority-class Proportion + Indices | 5 | -115.46 | 0.39 |
| Ancillary Data + Majority-class Proportion + Number of Spectral Bands | 6 | -114.42 | 0.23 |
| Ancillary Data + Majority-class Proportion | 4 | -114.13 | 0.20 |
| Ancillary Data + Confusion Matrix + Majority-class Proportion + Number of Spectral Bands | 7 | -113.08 | 0.12 |
| Ancillary Data + Majority-class Proportion + Number of Spectral Bands + Sample Size | 7 | -111.65 | 0.06 |
| Intercept-Only | 2 | -41.93 | 0.00 |
meta_reg_42 <- rma.mv(yi, vi,
data = ies.da ,
random = ~ 1 | AuthorYear / esid,
tdist = TRUE,
method = "REML",
test = "t",
dfs="contain",
mods = ~ fraction_majority_class+ancillary+ indices
)Table 4.4 shows the estimated coefficients for the best-fit model — i.e., the model with the lowest AIC value among the candidate models. The coefficients are presented both in the FT-transformed scale (b) and on the natural (back-transformed) scale. The results highlight that the proportion of the majority class has the largest positive effect (\(b = 0.39\), \(b^{BT} = 0.15\), p < .001). Suggesting that increasing the majority-class proportion significantly improves overall accuracy. While, the inclusion of ancillary data has a small negative effect on the FT-transformed scale (\(b = -0.11, p = 0.029\)) but shows a slight positive effect once back-transformed (\(b^{BF} = 0.01\)). The use of indices has a minimal and non-significant effect (\(p = 0.131\)).
backtras.function<- function(t_bar, se){
v_bar <- (se)^2
(1/2 * (1 - sign(cos(2*t_bar)) *
sqrt(1 - (sin(2*t_bar)+(sin(2*t_bar)-1/sin(2*t_bar))/(1/v_bar))^2)))
}
ci.function <- function(ci_l, ci_u, se){
back_ci_l = backtras.function(ci_l, se)
back_ci_u = backtras.function(ci_u, se)
out<- paste0("[", paste0(format(round(back_ci_l, 2), nsmall = 2)), ", ", # must be a better way
paste0(format(round(back_ci_u,2), nsmall = 2)), "]")
return(out)
}
coef_bestmod <-
meta_reg_42|>
tidy() |>
mutate(estimate_back_transfromed = mapply(backtras.function, meta_reg_42$b, meta_reg_42$se))|>
mutate(CI = mapply(ci.function, meta_reg_42$ci.lb,meta_reg_42$ci.ub, meta_reg_42$se))|>
select(term, estimate, std.error, statistic, p.value, estimate_back_transfromed, CI)
coef_bestmod$term <- factor(
coef_bestmod$term,
levels = c(
"intercept",
"fraction_majority_class",
"ancillaryAncillary Data Included",
"indicesUsed"
),
labels = c(
"Intercept",
"Majority-class Proportion",
"Ancillary Data: Included",
"Indices: Used"
)
)
coef_bestmod|>
kable(booktabs = TRUE,
linesep = "",
escape = FALSE,
col.names = c("Predictor", "b", "SE", "t", "p", "b$^{B-FT}$", "CI"),
digits = c(0, 2, 2, 2, 3, 2),
align = c("l", "r", "r", "r", "r", "r", "r")
) |>
kable_styling(font_size = 10,
full_width = FALSE)|>
add_header_above(c(" ","","","","", "back-transfromed scale" = 2)) |>
row_spec(c(0), bold = TRUE)|>
column_spec(1, width = "6cm")|>
footnote(c("The estimated coefficients (b), standard errors (SE) on the FT transformed scale, with correstponding t-statistics and p-values. Additionally, the coefficients ($b^{B-FT}$) and corresponding confidence intervals (CI) are shown on the back-transformed scale."), escape = FALSE, threeparttable=T)| Predictor | b | SE | t | p | b$^{B-FT}$ | CI |
|---|---|---|---|---|---|---|
| Intercept | 0.99 | 0.06 | 17.22 | 0.000 | 0.70 | [0.58, 0.80] |
| Majority-class Proportion | 0.39 | 0.08 | 4.93 | 0.000 | 0.15 | [0.05, 0.27] |
| Ancillary Data: Included | -0.11 | 0.05 | -2.22 | 0.029 | 0.01 | [0.04, 0.00] |
| Indices: Used | 0.06 | 0.04 | 1.53 | 0.131 | 0.00 | [0.00, 0.02] |
| Note: | ||||||
| The estimated coefficients (b), standard errors (SE) on the FT transformed scale, with correstponding t-statistics and p-values. Additionally, the coefficients ($b^{B-FT}$) and corresponding confidence intervals (CI) are shown on the back-transformed scale. |
To assess the impact of the study features on the estimated heterogeneity the features included in the best-fit model are fitted as sole covariates. Table 4.5 shows the parameter estimates from the meta-analysis, comparing the intercept-only model with four mixed-effects models, one for each of the features in the best-fit model and best-fit model itself.
meta_reg_anc <- rma.mv(yi, vi,
data = ies.da,
random = ~ 1 | AuthorYear / esid,
tdist = TRUE,
method = "REML",
test = "t",
dfs="contain",
mods = ~ ancillary)
meta_reg_frac <- rma.mv(yi, vi,
data = ies.da,
random = ~ 1 | AuthorYear / esid,
tdist = TRUE,
method = "REML",
test = "t",
dfs="contain",
mods = ~ fraction_majority_class)
meta_reg_ind <- rma.mv(yi, vi,
data = ies.da,
random = ~ 1 | AuthorYear / esid,
tdist = TRUE,
method = "REML",
test = "t",
dfs="contain",
mods = ~ indices)
extract_parameters <- function(model) {
out <- data.frame(
model = if (!is.null(model$formula.mods)) paste(model$formula.mods)[2] else "Intercept Only",
sig_lvl2 = round(model$sigma2[2], 3),
sig_lvl3 = round(model$sigma2[1], 3),
QE = round(model$QE,0),
df_Q = model$QEdf,
p_Q = round(model$QEp,3),
f_test = if (!is.null(model$formula.mods))
round(model$QM, 0)
else
NA,
df_F = if (!is.null(model$formula.mods))
model$QMdf[1]
else
NA,
p_F = if (!is.null(model$formula.mods))
round(model$QMp, 3)
else
NA,
I2_lvl2 = dmetar::var.comp(model)$results[2, 2],
I2_lvl3 = dmetar::var.comp(model)$results[3, 2],
R2_lvl2 = if (!is.null(model$formula.mods))
(round(1 - (model$sigma2[2] / pes.da.lvl3$sigma2[2]), 3) * 100)
else
NA,
R2_lvl3 = if (!is.null(model$formula.mods))
(round(1 - (model$sigma2[1] / pes.da.lvl3$sigma2[1]), 3) * 100)
else
NA
)
return(out)
}
heterogeneity_tbl <- rbind(extract_parameters(pes.da.lvl3),
extract_parameters(meta_reg_frac),
extract_parameters(meta_reg_anc),
extract_parameters(meta_reg_ind),
extract_parameters(meta_reg_42))
heterogeneity_tbl$model <- factor(heterogeneity_tbl$model,
levels = c("Intercept Only",
"fraction_majority_class",
"ancillary",
"indices",
"fraction_majority_class + ancillary + indices"),
labels = c("Intercept Only",
"Majority-class Proportion",
"Ancillary Data",
"Indices",
"Combinded model$^{\\text{a}}$"))
heterogeneity_tbl$p_Q <- ifelse(heterogeneity_tbl$p_Q <0.0001,
"<.0001",
heterogeneity_tbl$p_Q)
kable(
heterogeneity_tbl,
booktabs = TRUE,
escape = FALSE,
linesep = "",
col.names = c("Model",
"$\\sigma^2_{\\text{level2}}$", "$\\sigma^2_{\\text{level3}}$",
"$Q_E$", "df", "$p_Q$", "$F$", "df", "$p_F$",
"$I^2_{\\text{level2}}$", "$I^2_{\\text{level3}}$",
"$R^2_{\\text{level2}}$", "$R^2_{\\text{level3}}$"),
align = c("l", "r","r","r","r","r","r", "r","r","r","r","r","r")
)|>
kable_styling(font_size = 9,
full_width = FALSE)|>
row_spec(c(0), bold = TRUE)|>
#column_spec(1, width = "4cm")|>
#column_spec(c(2,3,10:13), width = "0.8cm")|>
#column_spec(c(5,7,8), width = "0.1cm")|>
footnote(general = "Test statistic, degrees of freedom and respective p values are provide. This table allows heterogeneity at level 2 and 3 can be compared between the incetept only model, Majority-class Proportion and Adncillary Data only models, as well as the combinded model",
alphabet = "Combinded model: Ancillary Data + Majority-class Proportion + Indices", threeparttable=TRUE)| Model | $\sigma^2_{\text{level2}}$ | $\sigma^2_{\text{level3}}$ | $Q_E$ | df | $p_Q$ | $F$ | df | $p_F$ | $I^2_{\text{level2}}$ | $I^2_{\text{level3}}$ | $R^2_{\text{level2}}$ | $R^2_{\text{level3}}$ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Intercept Only | 0.010 | 0.017 | 12161784 | 85 | <.0001> | NA | NA | NA | 36.38 | 63.62 | NA | NA |
| Majority-class Proportion | 0.009 | 0.007 | 11458055 | 84 | <.0001> | 27 | 1 | 0.000 | 57.29 | 42.71 | 7.8 | 60.7 |
| Ancillary Data | 0.010 | 0.015 | 12035286 | 84 | <.0001> | 3 | 1 | 0.117 | 40.47 | 59.53 | -1.4 | 14.7 |
| Indices | 0.010 | 0.018 | 11986674 | 84 | <.0001> | 3 | 1 | 0.100 | 34.26 | 65.74 | 3.6 | -5.8 |
| Combinded model$^{\text{a}}$ | 0.009 | 0.005 | 11440331 | 82 | <.0001> | 13 | 3 | 0.000 | 63.46 | 36.54 | 8.6 | 69.9 |
| Note: | ||||||||||||
| Test statistic, degrees of freedom and respective p values are provide. This table allows heterogeneity at level 2 and 3 can be compared between the incetept only model, Majority-class Proportion and Adncillary Data only models, as well as the combinded model | ||||||||||||
| a Combinded model: Ancillary Data + Majority-class Proportion + Indices |
As shown in Table 4.5, the Majority-class Proportion explains a greater proportion of the between-study heterogeneity, as indicated by the reduction in \(\sigma^2_{\text{level2}}\) between the intercept-only model and the model with the Majority-class Proportion. In contrast, the use of Ancillary Data explains relatively little between-study heterogeneity and negligible within-study heterogeneity.
The combined model (best-fit model) explains the most heterogeneity overall, as reflected in the shift in \(I^2\) values. The total \(I^2\), consistently at 100% across all models, suggests that nearly all the variation in effect sizes is due to differences between the studies, rather than sampling error. This observation raises the possibility of an “apples and oranges” problem (see the discussion section), where the included studies may be too heterogeneous to be meaningfully compared.
All models show significant heterogeneity, with Cochran’s Q test results being significant (p < 0.001). The \(R^2\) values indicate that the covariates in the combined mixed-effects model account for 69.9% of the variance at level 3 (between-study level) and 8.6% of the variance at level 2 (within-study level).
Figure 4.7 illustrates the relationship between the proportion of the majority class and overall accuracy of the individual studies included in the meta-analysis. The plot is based on the combined mixed-effects model, where the solid black line represents the fitted regression line, and the shaded area indicates the 95% confidence interval. Each point (or bubble) represents an individual study, with the size of each bubble proportional to the weight it received in the analysis (i.e., larger points represent studies that had more influence on the overall results). The plot demonstrates a clear trend: as the proportion of the majority class increases, overall accuracy tends to improve, indicating a positive correlation between these two variables.
library(RColorBrewer)
colors <- c(brewer.pal(9, "Pastel1"), brewer.pal(12, "Set3"))
authors <- unique(ies.da$AuthorYear)
author_colors <- setNames(colors[1:length(authors)], authors)
ies.da$color <- author_colors[ies.da$AuthorYear]
# labels
ies.da <- tibble::rowid_to_column(ies.da, "effectsizeID")
lowest_yi_per_author <- ies.da |>
group_by(AuthorYear) |>
filter(yi == min(yi)) |>
select(AuthorYear, effectsizeID)
# 2 level mod
png(file="fig-bubble_lvl3.png", width=700, height=800)
bubble_plot_3lvl <- regplot(meta_reg_42,
mod = "fraction_majority_class",
transf = transf.ipft.hm, targ =list(ni=1/(meta_reg_42$se)^2),
xlab = "Proportion of majority class",
ylab = "Overall Accuracy",
slab = ies.da$AuthorYear,
label = lowest_yi_per_author$effectsizeID,
labsize = 1,
bg=ies.da$color,
xlim=c(0.05, 1.05),
ylim=c(0.64, 1))
dev.off()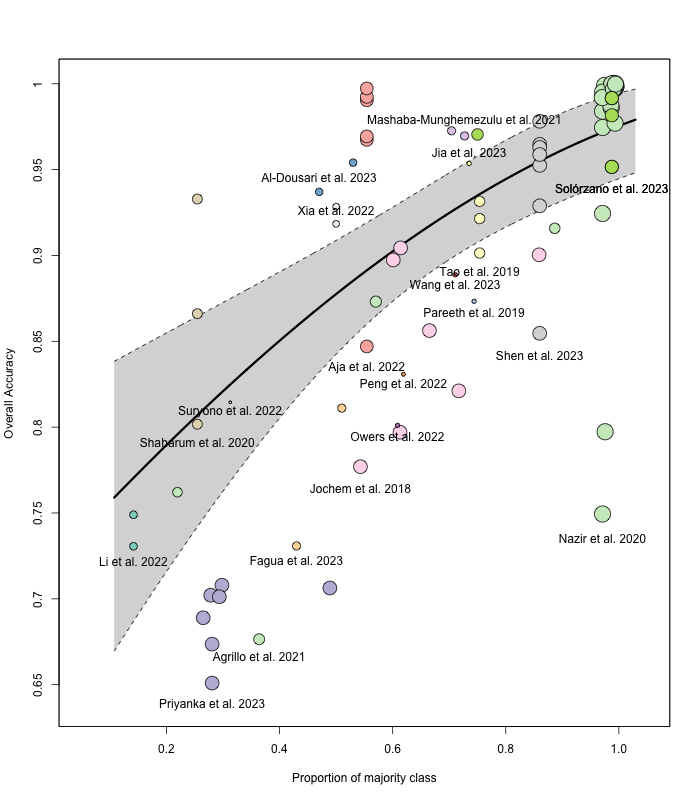
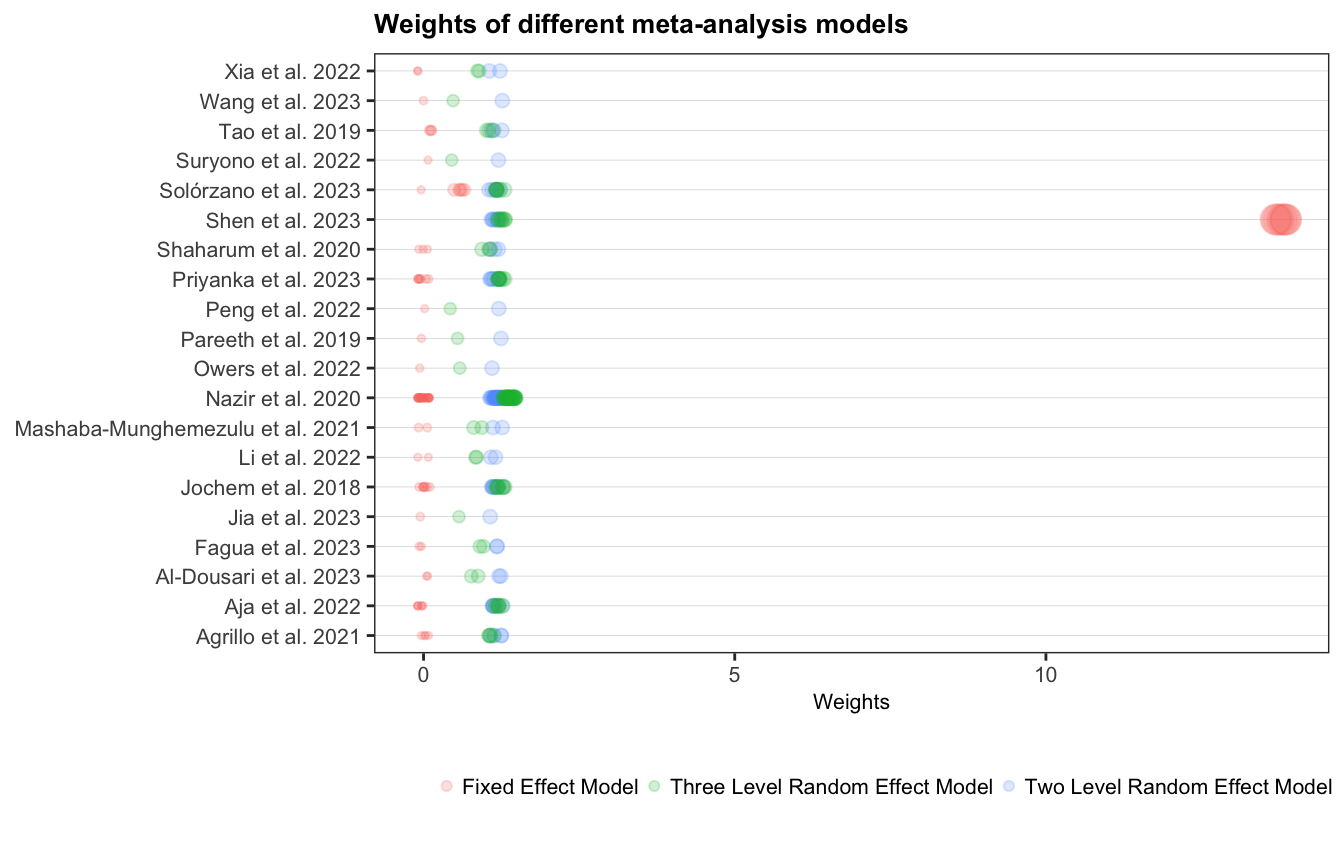
The size of the points in the bubble plot illustrates the benefit of incorporating the structure of the data into meta-analytic weighting. Namely, that the difference in size of the bubbles are not exessive. Figure 4.8 highlights this by plotting the weights for each study from a fixed effect, random effect with two levels and the structure used here, the random effects with three levels. As shown, the fixed-effects model particularity as one study is heavily weighted, which can distort the overall results. In contrast, the two-level and three-level models distribute the weights more evenly across studies, reflecting the importance of accounting for between-study heterogeneity and within-study variation.
# Fixed-effect model (only within-study variance)
FE_mod <- rma(yi, vi, method = "FE", data = ies.da)
ies.da$w_FE <- weights(FE_mod)
# 2 level meta analysis weights
ies.da$w_RE2 <- weights(pes.da)
# 3 level meta analysis weights
ies.da$w_RE3 <- weights(pes.da.lvl3)
ggplot(ies.da, aes(x = factor(AuthorYear)))+
geom_jitter(aes(y = w_FE, size = w_FE, colour = "Fixed Effect Model"),
alpha = 0.2, width = 0, height = 0.1)+
geom_jitter(aes(y = w_RE2, size = w_RE2, colour = "Two Level Random Effect Model"),
alpha = 0.2, width = 0, height = 0.1)+
geom_jitter(aes(y = w_RE3, size = w_RE3, colour = "Three Level Random Effect Model"),
alpha = 0.2, width = 0, height = 0.1)+
scale_size_continuous(range = c(1, 5), breaks = c(0.5, 0.8, 1.1, 1.4,1.5, 2))+
coord_flip() +
labs(x = NULL,
y = "Weights",
title = "Weights of different meta-analysis models") +
guides(size = "none")+
common_theme+
theme(# grid lines
panel.grid.major.y = element_line(linewidth = 0.1, colour = "grey80"),
# legend specs
legend.position = "bottom",
legend.text= element_text(size=8, margin = margin(l = -0.3, r = -0.5, unit = "cm"))
) 
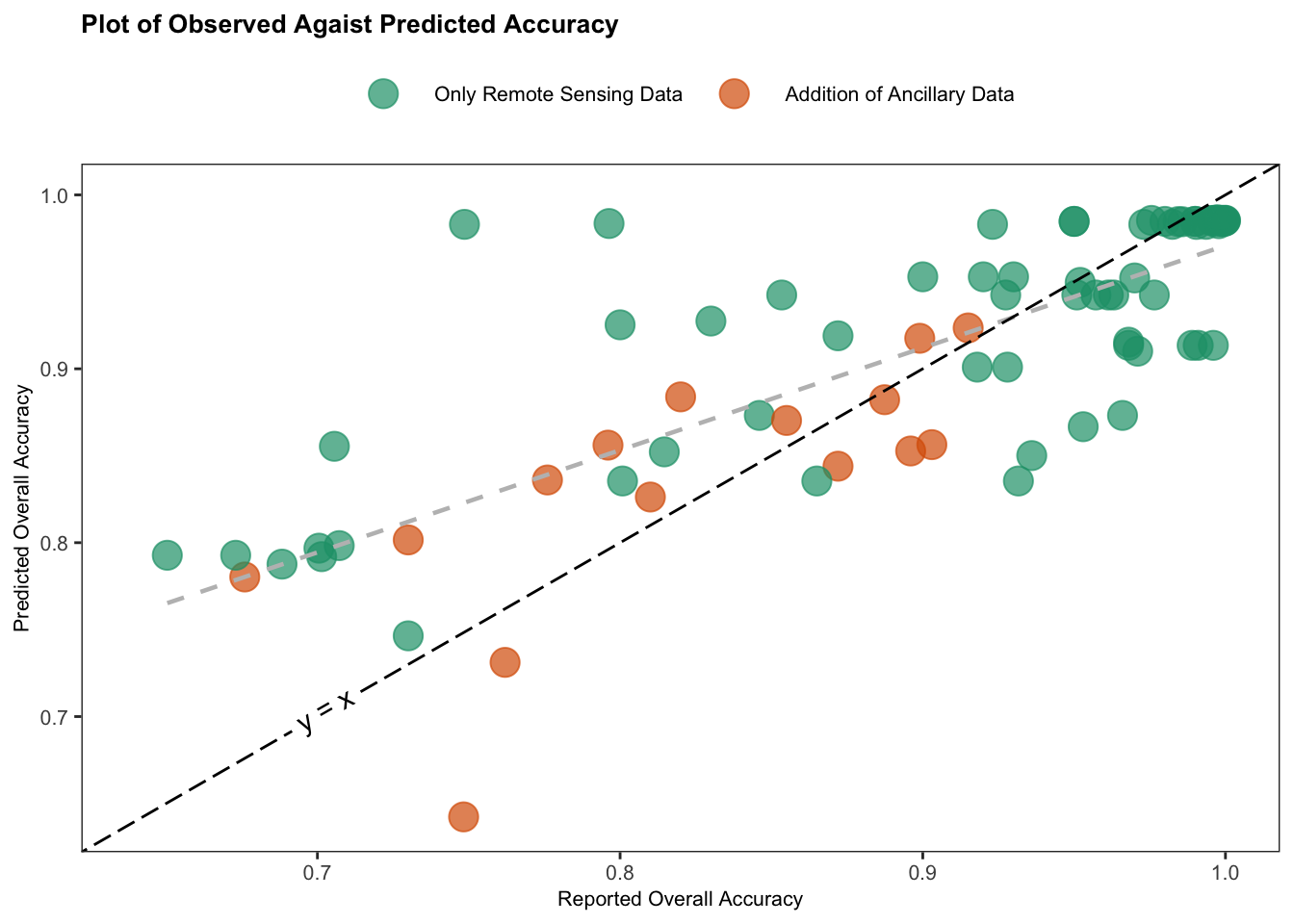
Lastly, Figure 4.9 is a plot of observed overall accuracy against the predicted overall accuracy from the combined mixed-effects model. The points are colored based on whether ancillary information was included in the primary study. As Figure 4.9 illustrates, the combined mixed-effects model tends to overestimate overall accuracy — the fitted regression line (in grey) lies above the line of perfect agreement (y = x, in black), indicating that the model’s predictions are generally higher than the observed accuracy values.
ies.da$preds <- predict(meta_reg_42, transf = transf.ipft.hm, targ =list(ni=1/(meta_reg_42$se)^2))$pred
ggplot(ies.da, aes(x = OA_reported, y = preds))+
geom_point(size = 5, aes(colour = ancillary), alpha = 0.7)+
geom_smooth(method = "lm",formula = 'y ~ x', se = FALSE, colour = "grey", linetype= "dashed", linewidth = 0.8)+
# y = x line
geom_textabline(label = "y = x", intercept = 0, slope = 1,hjust = 0.2, linetype= "longdash")+
scale_colour_brewer(palette = "Dark2",
labels = c("Only Remote Sensing Data","Addition of Ancillary Data"))+
xlim(c(0.64, 1))+
ylim(c(0.64,1))+
labs(x = "Reported Overall Accuracy",
y = "Predicted Overall Accuracy",
title = "Plot of Observed Agaist Predicted Accuracy")+
theme(legend.text = element_text(size = 8),
legend.position = "top") +
common_themeggsave("fig-preds.png", width = 15,
height = 10,
units = "cm")